

TL;DR Voice AI systems are transforming how businesses interact with customers. The technology powers everything from customer service bots to smart home assistants. But there’s a critical component that often gets overlooked: the underlying infrastructure.
Voice AI clustering architecture represents the backbone of scalable, reliable voice systems. It’s not just about making AI understand speech. It’s about ensuring that understanding happens consistently, quickly, and without fail—even when thousands of users speak simultaneously.
Most companies learn about clustering the hard way. They launch a voice AI solution that works perfectly in testing. Then real users flood in. The system crashes. Calls drop. Customers get frustrated. Revenue takes a hit.
This comprehensive guide explores why voice AI clustering architecture deserves your attention before you go live. We’ll dive into the technical foundations, real-world implementations, and critical decisions that separate successful deployments from expensive failures.
Table of Contents
Understanding the Fundamentals of Voice AI Systems
Voice AI technology has evolved dramatically over the past decade. Early systems could barely recognize simple commands. Modern solutions understand context, emotion, and even regional accents.
At its core, voice AI combines several complex processes. Speech recognition converts audio into text. Natural language processing interprets meaning. Text-to-speech generates responses. Each step requires significant computational power.
A single voice interaction might seem simple to users. Behind the scenes, the system processes thousands of calculations per second. It analyzes audio frequencies, matches patterns against vast databases, and generates contextually appropriate responses.
The challenge multiplies when you scale. One user? Easy. Ten thousand simultaneous users? That’s where most systems break down without proper architecture.
The Processing Pipeline Explained
Voice AI systems follow a structured pipeline. Audio input arrives first, often in compressed formats to save bandwidth. The system must decode this audio while preserving quality.
Speech recognition engines then analyze the waveform. They segment the audio into phonemes, the smallest units of sound. Machine learning models match these patterns against trained data.
Natural language understanding comes next. The system doesn’t just transcribe words. It interprets intent, extracts entities, and maintains conversation context. This step often requires the most computational resources.
Finally, response generation occurs. The AI formulates an appropriate answer, converts it to speech, and streams it back to the user. Latency at any stage creates a poor user experience.
Why Single-Server Deployments Fail
Many teams start with a single powerful server. The logic seems sound: one machine handles everything, keeping complexity low. This approach works until it doesn’t.
Server hardware has physical limits. CPU cores can only process so many requests. Memory fills up. Network interfaces hit bandwidth caps. Adding more RAM or faster processors only delays the inevitable.
Redundancy becomes impossible with single-server setups. Hardware fails. Software crashes. Updates require downtime. In production environments, these issues translate directly to lost business.
Geographic distribution poses another problem. Users in Asia connecting to a server in Virginia experience significant latency. Voice conversations demand near-instantaneous responses. Even 200 milliseconds of delay feels unnatural.
The Core Principles of Voice AI Clustering Architecture
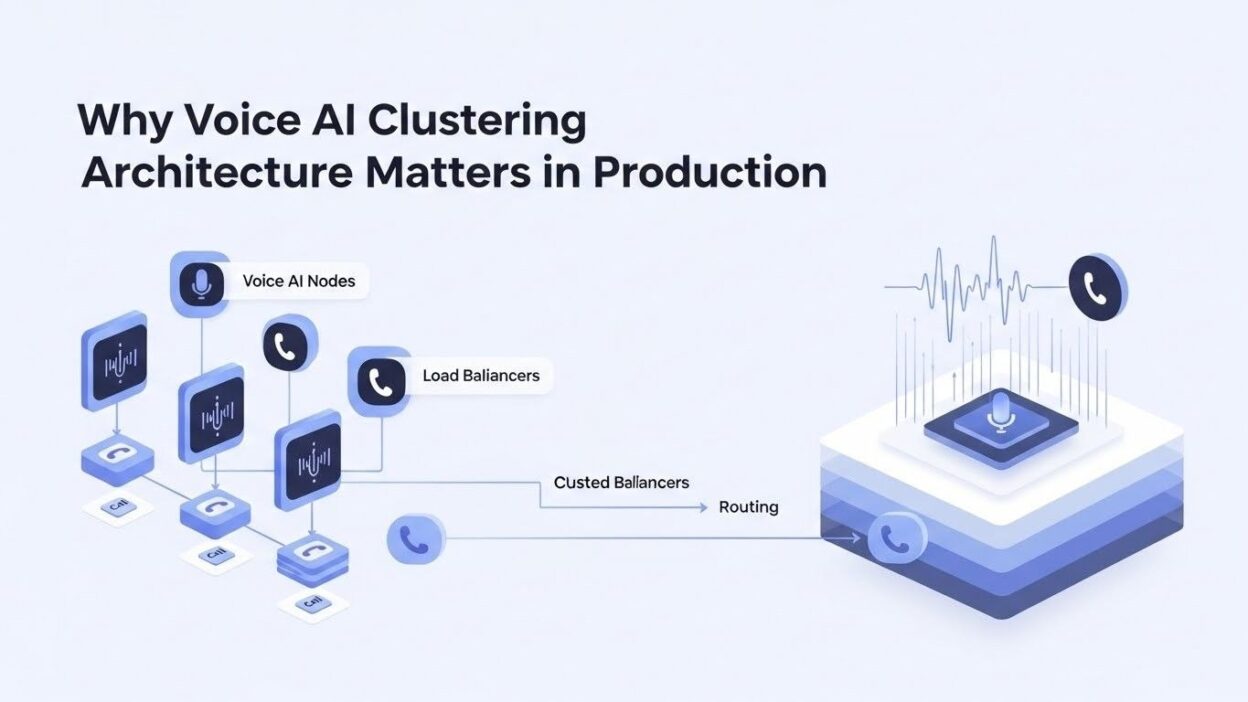
Voice AI clustering architecture distributes workload across multiple servers working in concert. Each node in the cluster handles a portion of the total traffic. The system automatically routes requests to available resources.
Clustering transforms voice AI from a fragile single point of failure into a resilient distributed system. If one server goes down, others immediately absorb its workload. Users never notice the transition.
The architecture enables horizontal scaling. Need more capacity? Add more nodes. The cluster automatically incorporates new resources without downtime or reconfiguration.
Load balancing ensures efficient resource utilization. Smart algorithms distribute incoming requests based on current server load, geographic proximity, and specialized capabilities. No single node becomes overwhelmed while others sit idle.
Distributed Processing Models
Different clustering approaches suit different needs. Shared-nothing architectures give each node complete independence. Nodes don’t share memory or storage, maximizing resilience but increasing complexity.
Shared-storage models allow multiple nodes to access common data. This simplifies state management but creates potential bottlenecks. The storage layer must scale alongside compute resources.
Hybrid approaches combine both strategies. Frequently accessed data lives in local caches for speed. Persistent state synchronizes across a distributed storage layer. Most production systems adopt this middle ground.
Microservices architectures take distribution further. Speech recognition, NLP, and synthesis run as independent services. Each component scales independently based on demand. This modularity enables fine-grained optimization.
Communication Between Cluster Nodes
Nodes must coordinate efficiently. Message queues facilitate asynchronous communication, allowing services to operate independently while maintaining data flow.
Service meshes provide sophisticated networking layers. They handle service discovery, load balancing, encryption, and monitoring. Tools like Istio or Linkerd abstract away much of this complexity.
State synchronization presents unique challenges. Voice conversations maintain context across multiple turns. The system must ensure that subsequent requests from the same user reach nodes with relevant context.
Session affinity mechanisms route related requests to the same node when possible. When that node fails, the system must quickly reconstruct session state elsewhere. This requires careful architecture planning.
Real-World Benefits of Proper Voice AI Clustering Architecture
Companies implementing robust voice AI clustering architecture report dramatic improvements across multiple metrics. Uptime increases from 95% to 99.99% or better. Response times drop by 60-80%. Customer satisfaction scores climb proportionally.
The financial impact extends beyond user experience. Downtime costs vary by industry, but even small businesses lose thousands per hour. Enterprise systems can hemorrhage millions during major outages.
Scalability enables business growth. Marketing launches that drive traffic spikes no longer trigger panic. Seasonal demand fluctuations get absorbed automatically. Geographic expansion happens without infrastructure overhauls.
Performance Optimization Through Distribution
Geographic distribution reduces latency significantly. A well-designed voice AI clustering architecture places compute resources near users. Asian users hit Asian servers. European traffic stays in Europe.
This proximity matters more for voice than traditional applications. Humans detect audio delays above 150 milliseconds. Round-trip network latency alone can exceed this threshold on intercontinental connections.
Edge computing takes distribution to the extreme. Voice AI processing happens on local servers or even user devices. Only complex processing or data synchronization travels to central clouds.
Caching strategies complement distribution. Frequently requested responses live in fast local storage. Common wake words trigger locally without cloud roundtrips. This reduces both latency and bandwidth costs.
High Availability and Disaster Recovery
Hardware failures happen constantly in large deployments. Hard drives die. Memory modules fail. Network switches lose power. Voice AI clustering architecture treats failure as normal, not exceptional.
Automatic failover mechanisms detect problems within seconds. Health checks continuously verify node responsiveness. Failed nodes get removed from rotation instantly. Traffic reroutes to healthy alternatives.
Data replication ensures no information loss. User preferences, conversation histories, and training data exist across multiple nodes. Even if an entire data center burns down, service continues uninterrupted.
Geographic redundancy protects against regional outages. Natural disasters, power grid failures, and network partitions affect specific areas. Multi-region clusters maintain service through any single region’s problems.
Technical Components of Effective Clustering
Building production-ready voice AI clustering architecture requires multiple technical layers working together. Each component serves specific purposes while integrating into the larger system.
Load balancers form the entry point. They accept incoming requests and distribute them across available nodes. Modern load balancers make intelligent decisions based on real-time metrics.
Container orchestration platforms like Kubernetes manage the cluster itself. They schedule workloads, monitor health, scale resources, and handle failures automatically. These platforms have become standard for distributed systems.
Load Balancing Strategies
Round-robin distribution offers the simplest approach. Each request goes to the next server in sequence. This works well when all nodes have identical capabilities and requests have similar resource requirements.
Least-connections routing sends requests to nodes with the fewest active connections. This accounts for varying request complexity. Long-running voice sessions don’t unfairly burden specific servers.
Weighted distribution acknowledges that nodes may have different capacities. Powerful servers receive more traffic than modest ones. Weighting factors adjust dynamically based on observed performance.
Geographic routing considers user location. A comprehensive voice AI clustering architecture includes location-aware load balancing. Users automatically connect to nearby data centers for optimal latency.
Container Orchestration and Kubernetes
Kubernetes has become the de facto standard for managing distributed applications. It abstracts away much infrastructure complexity while providing powerful automation.
Pods represent the basic deployment unit. Each pod runs one or more containers sharing resources. Voice AI deployments typically separate speech recognition, NLP, and synthesis into distinct pods.
Services provide stable networking endpoints. Individual pods come and go as the system scales or recovers from failures. Services ensure other components can reliably communicate regardless of pod churn.
Horizontal pod autoscaling adjusts capacity based on metrics. CPU usage, memory consumption, or custom metrics like queue depth trigger automatic scaling. The cluster expands during peak hours and contracts overnight, optimizing costs.
Monitoring and Observability
You can’t optimize what you can’t measure. Comprehensive monitoring forms the foundation of reliable voice AI clustering architecture.
Metrics collection tracks system health in real time. Request rates, error percentages, response times, and resource utilization flow into centralized monitoring platforms. Prometheus and Grafana are popular choices.
Distributed tracing follows individual requests through the system. A single voice interaction might touch dozens of services. Tracing tools like Jaeger reveal exactly where latency or errors occur.
Logging provides detailed debugging information. Structured logs from all cluster nodes aggregate into searchable repositories. When problems arise, engineers can quickly locate relevant information across the entire distributed system.
Designing Your Voice AI Clustering Architecture
Every organization has unique requirements. Successful voice AI clustering architecture designs balance performance, cost, complexity, and business needs.
Start by defining clear requirements. Expected user volume, latency targets, uptime goals, and budget constraints shape architectural decisions. A startup with 1,000 users needs different infrastructure than an enterprise with millions.
Consider your team’s expertise. Sophisticated distributed systems require specialized knowledge. Managed services can provide enterprise-grade capabilities without building in-house expertise.
Capacity Planning Fundamentals
Accurate capacity planning prevents both over-provisioning and under-provisioning. Over-provisioning wastes money on unused resources. Under-provisioning leads to performance problems and outages.
Analyze expected traffic patterns. Daily cycles, weekly variations, and seasonal fluctuations all impact required capacity. Marketing campaigns and product launches create predictable spikes.
Establish baseline resource requirements. Test individual voice interactions under controlled conditions. Measure CPU, memory, network, and storage consumption. Multiply by expected concurrent users.
Add generous headroom. Real-world usage always exceeds estimates. Network overhead, inefficiencies, and unexpected load patterns consume resources. Plan for 2-3x your calculated baseline as a starting point.
Choosing Between Cloud and On-Premises
Cloud platforms offer compelling advantages for voice AI clustering architecture. Major providers like AWS, Google Cloud, and Azure provide managed services handling much infrastructure complexity.
Elasticity enables perfect capacity matching. Scale up instantly during traffic surges. Scale down when demand drops. Pay only for resources actually consumed. This flexibility dramatically reduces operational costs.
Global presence solves geographic distribution. Major clouds operate data centers worldwide. Deploy your voice AI system across continents with minimal effort. Users everywhere get low-latency access.
On-premises deployments suit specific scenarios. Highly regulated industries may require data to stay within controlled facilities. Some organizations have substantial existing infrastructure investments worth leveraging.
Hybrid approaches combine both worlds. Sensitive operations run on-premises. Scalable compute bursts into the cloud during peaks. This balances control, compliance, and cost-effectiveness.
Security Considerations in Distributed Systems
Security complexity increases with distribution. More network connections mean more potential attack vectors. Voice AI clustering architecture must incorporate security at every layer.
Network segmentation isolates components. Public-facing load balancers sit in one zone. Application servers occupy another. Databases live in protected enclaves. Firewalls strictly control permitted communication.
Encryption protects data in transit. TLS secures all network connections between services. Voice data, user credentials, and session information never traverse networks unencrypted.
Authentication and authorization mechanisms verify every request. API keys, OAuth tokens, or mutual TLS certificates ensure only authorized components communicate. Zero-trust architectures assume no internal network is inherently safe.
Regular security audits identify vulnerabilities. Automated scanning tools check for known issues. Penetration testing simulates real attacks. Security patches deploy rapidly across all cluster nodes simultaneously.
Implementation Challenges and Solutions
Building production-grade voice AI clustering architecture presents numerous challenges. Recognizing common pitfalls helps you avoid expensive mistakes.
State management causes many problems. Voice conversations maintain context across multiple exchanges. Ensuring this context remains available as requests move between nodes requires careful design.
Managing Conversational State
Stateless designs simplify clustering. Each request contains all necessary context. Nodes don’t need to remember previous interactions. This approach scales beautifully but increases bandwidth and processing requirements.
Sticky sessions route a user’s requests to the same node. This simplifies state management but reduces flexibility. If that node fails, the conversation must start over or state must be recovered from elsewhere.
Distributed caching provides middle ground. Redis or Memcached clusters store session state separately from application nodes. Any node can retrieve context for any user. This enables both flexibility and performance.
Database-backed state offers the most durability. Every conversation update persists to a database. This ensures no data loss but introduces latency. Combining database persistence with caching delivers both speed and reliability.
Handling Model Deployment and Updates
Machine learning models powering voice AI require regular updates. New training data improves accuracy. Bug fixes address edge cases. Feature additions enable new capabilities.
Rolling updates minimize disruption. Update a subset of nodes while others continue serving traffic. Verify the new version works correctly before updating remaining nodes. This prevents bad updates from affecting all users.
Blue-green deployments run two complete environments. The blue environment serves production traffic. Green receives the update. After validation, traffic switches to green. Blue becomes the new staging environment.
Canary deployments expose updates to a small user percentage first. Monitor error rates and performance metrics. Gradually increase the rollout if metrics look good. Rollback immediately if problems appear.
Debugging Distributed Systems
Troubleshooting voice AI clustering architecture challenges traditional debugging approaches. Problems often emerge from interactions between components rather than bugs in single services.
Correlation IDs track requests across services. A unique identifier attaches to each incoming request. Every log entry, metric, and trace includes this ID. Engineers can follow a problematic request’s complete journey through the system.
Synthetic monitoring proactively detects issues. Automated tests continuously exercise the system from user perspectives. These tests catch problems before real users encounter them.
Chaos engineering validates resilience. Deliberately introduce failures into the system. Kill random nodes. Inject network latency. Simulate data center outages. Verify the system recovers gracefully. Netflix pioneered this approach with their Chaos Monkey tool.
Cost Optimization Strategies
Effective voice AI clustering architecture balances performance with cost. Overspending on infrastructure erodes profitability. Under-investing creates poor user experiences.
Right-sizing instances prevents waste. Cloud providers offer dozens of instance types. Match computational requirements to available options. CPU-intensive speech recognition needs different hardware than memory-intensive NLP.
Autoscaling for Cost Efficiency
Autoscaling reduces idle capacity costs. Traffic fluctuates throughout the day. A system sized for peak load wastes money during valleys. Autoscaling continuously adjusts capacity to current demand.
Schedule-based scaling handles predictable patterns. Reduce capacity overnight when users sleep. Increase capacity before known traffic spikes. This proactive approach prevents performance problems while minimizing costs.
Metrics-based scaling reacts to actual demand. CPU utilization, request queue length, or custom metrics trigger scaling actions. The system automatically adapts to unexpected load changes.
Cool-down periods prevent scaling thrash. Rapid scaling up and down wastes resources and creates instability. Cool-down timers ensure the system stabilizes before additional scaling actions occur.
Resource Allocation Best Practices
CPU and memory requests tell the orchestrator minimum resource needs. Limits define maximum consumption. Setting these correctly ensures stable performance while enabling efficient node packing.
Over-requesting resources wastes capacity. The orchestrator may only schedule a few pods per node even when resources sit idle. Under-requesting leads to performance problems and out-of-memory crashes.
Profiling your voice AI clustering architecture under realistic loads reveals actual resource consumption. Use these measurements to set appropriate requests and limits. Revisit periodically as your application evolves.
Spot instances offer significant discounts. Cloud providers sell spare capacity at reduced rates. Spot instances may be reclaimed with short notice. Use them for stateless, interruptible workloads. Maintain stable nodes for critical services.
Future Trends in Voice AI Infrastructure
The voice AI field continues evolving rapidly. Emerging technologies will reshape voice AI clustering architecture over coming years.
Edge computing pushes processing closer to users. Smart speakers, phones, and vehicles gain enough power to run AI models locally. Central clouds handle complex requests and model training. Local processing handles common cases with minimal latency.
Specialized Hardware Acceleration
GPUs revolutionized machine learning training. Inference workloads benefit from specialized chips. Google’s TPUs, AWS Inferentia, and various AI accelerators deliver better performance per dollar than general-purpose CPUs.
Integrating accelerators into voice AI clustering architecture requires platform support. Kubernetes can schedule workloads onto nodes with specific hardware. Pods request GPU or TPU resources like they request CPU and memory.
Mixed hardware clusters optimize costs. Use expensive accelerators only for components that benefit. Run orchestration, networking, and storage on standard instances. This heterogeneous approach maximizes efficiency.
WebAssembly for Cross-Platform Deployment
WebAssembly enables running compiled code in browsers and at edge locations. Voice AI components compiled to WASM can run anywhere without modification.
This portability simplifies deployment across diverse environments. The same voice AI clustering architecture logic runs in browsers, mobile apps, and edge servers. Maintenance complexity drops significantly.
Security improves through sandboxing. WASM modules run in isolated environments with limited capabilities. This reduces the attack surface compared to native code execution.
Measuring Success and ROI
Investment in proper voice AI clustering architecture must deliver measurable business value. Track metrics that demonstrate impact.
System reliability directly affects revenue. Calculate the cost per hour of downtime. Multiply by hours of downtime prevented. This quantifies the value of improved uptime.
Key Performance Indicators
Response time impacts user satisfaction. Measure 50th, 95th, and 99th percentile latencies. Users care most about worst-case scenarios. A system averaging 100ms but occasionally taking 5 seconds frustrates users.
Success rate indicates overall health. What percentage of voice interactions complete successfully? Track errors by type. Distinguish between user errors (unclear speech) and system failures (crashes, timeouts).
Throughput measures capacity. How many concurrent voice sessions can your voice AI clustering architecture handle? Test regularly as traffic grows. Identify bottlenecks before they impact production.
Cost per interaction reveals efficiency. Divide infrastructure costs by successful interactions. Track this metric over time. Well-optimized systems show decreasing costs as they mature.
User Experience Metrics
Net Promoter Score quantifies user satisfaction. Ask users how likely they’d recommend your voice AI service. Track NPS over time as you improve infrastructure and features.
Task completion rate measures effectiveness. Do users accomplish their goals? Voice AI shouldn’t just respond quickly. It should help users succeed. Architecture impacts this indirectly through reliability and performance.
Conversation length indicates natural interaction. Very short conversations may indicate user frustration causing early abandonment. Extremely long conversations suggest the AI isn’t understanding requests efficiently.
Read More:-Common Mistakes When Retraining Speech Recognition Models
Conclusion

Voice AI clustering architecture separates successful production deployments from failed experiments. The technology stack must handle real-world complexity that never appears during development.
A well-designed distributed system delivers consistent performance regardless of load. Users across the globe experience fast responses and reliable service. The infrastructure scales automatically as your business grows.
The investment in proper architecture pays dividends immediately. Reduced downtime prevents revenue loss. Improved performance drives user satisfaction. Geographic distribution enables global expansion. Automatic scaling optimizes costs.
Start with clear requirements. Understand your user base, traffic patterns, and business constraints. These factors guide architectural decisions. A system designed for 1,000 users looks completely different from one built for 10 million.
Leverage existing platforms and tools. Kubernetes, cloud services, and monitoring solutions provide enterprise-grade capabilities without building from scratch. Focus your team’s efforts on voice AI innovation, not infrastructure basics.
Plan for failure at every level. Hardware dies. Software crashes. Networks partition. Your voice AI clustering architecture should assume these events will happen and handle them gracefully.
Monitor everything. You cannot improve what you don’t measure. Comprehensive observability reveals performance issues, capacity constraints, and optimization opportunities. Make decisions based on data, not assumptions.
Security cannot be an afterthought. Distributed systems increase attack surface. Build security into every architectural layer. Regular audits and testing ensure protections remain effective as threats evolve.
The field continues advancing rapidly. Edge computing, specialized hardware, and new deployment models will reshape best practices. Stay informed about emerging technologies. Evaluate how they might improve your infrastructure.
Remember that voice AI clustering architecture serves your business goals. Technology choices should align with user needs and financial realities. The most sophisticated system provides no value if it costs more than it generates.
Start simple and evolve. You don’t need to implement every advanced feature on day one. Build a solid foundation. Add sophistication as your requirements become clear through production experience.
Testing under realistic conditions prevents expensive surprises. Synthetic load testing reveals capacity limits. Chaos engineering validates resilience. Invest time in validation before launching to real users.
Document your architecture thoroughly. Team members need to understand system design. Future engineers will appreciate clear explanations of architectural decisions. Good documentation accelerates troubleshooting and evolution.
The journey from simple prototype to production-ready voice AI clustering architecture requires careful planning and execution. But the results speak for themselves through happy users, stable operations, and sustainable business growth.
Your voice AI system represents the face of your company to users. Invest in the infrastructure that ensures it always puts your best foot forward. The architectural decisions you make today will impact your success for years to come.


