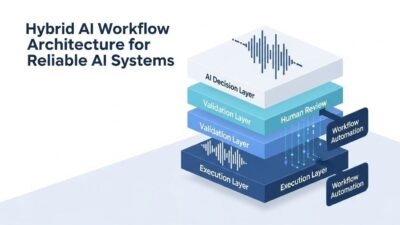
Introduction
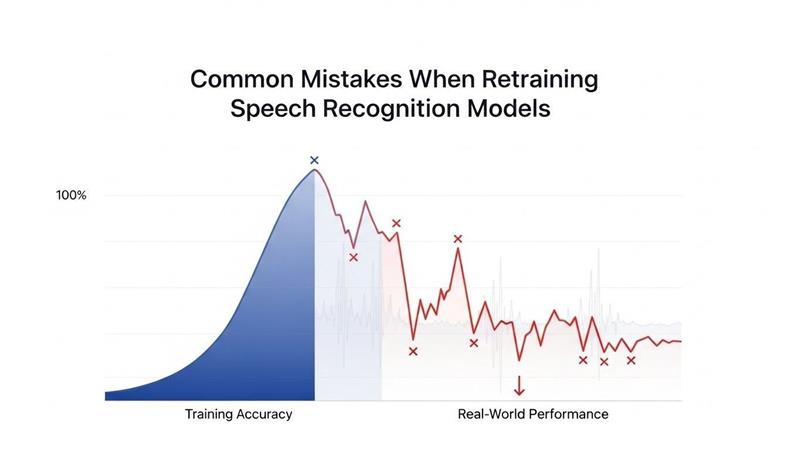
TL;DR Your speech recognition accuracy just dropped after retraining. The model performed better before the update. Users complain about increased transcription errors. Your team spent weeks collecting new data and training.
This frustrating scenario happens more often than teams expect. Organizations invest heavily in retraining speech recognition models. They gather audio samples, annotate transcripts, and run training pipelines. The results disappoint despite significant effort and expense.
Most failures stem from preventable mistakes. Teams overlook critical data quality issues. They choose wrong hyperparameters for their specific use case. Training procedures ignore domain-specific requirements. Small oversights cascade into major performance problems.
This guide reveals the common pitfalls that derail speech recognition retraining. You’ll discover specific mistakes that waste time and resources. More importantly, you’ll learn practical solutions that actually improve model performance. Your next retraining effort deserves to succeed.
Table of Contents
Understanding Speech Recognition Retraining Fundamentals
Speech recognition models learn patterns from training data. Initial training creates baseline capabilities. Retraining updates models with new information and improved techniques.
Organizations retrain models for several critical reasons. Domain-specific vocabulary requires specialized training. Accent diversity demands expanded audio samples. New features need additional capabilities. Performance degradation over time necessitates updates.
The retraining process involves multiple technical stages. Data collection gathers relevant audio samples. Preprocessing cleans and normalizes recordings. Feature extraction creates model inputs. Training updates neural network weights. Evaluation measures performance improvements.
Different retraining approaches suit different situations. Fine-tuning adjusts existing model weights slightly. Full retraining rebuilds models from scratch. Transfer learning adapts pre-trained models. Continual learning incorporates new data progressively.
Understanding when to retrain proves just as important. Declining accuracy metrics signal retraining needs. New use cases require model adaptation. User feedback reveals systematic errors. Regular scheduled retraining maintains performance.
The stakes run high for retraining decisions. Production systems depend on model accuracy. Poor retraining wastes computational resources. Failed updates frustrate users immediately. Getting retraining speech recognition models right matters tremendously.
Insufficient Training Data Volume
Many teams underestimate data requirements for effective retraining. They collect dozens of hours when models need hundreds. This fundamental shortage dooms retraining efforts from the start.
Modern neural speech recognition demands massive datasets. State-of-the-art models train on thousands of hours. Smaller datasets cannot capture linguistic diversity. Rare words and phrases need multiple examples. Statistical learning requires substantial samples.
Calculating exact data needs depends on multiple factors. Model architecture determines minimum requirements. Task complexity affects necessary volume. Starting model quality influences additional needs. Domain specificity changes data demands significantly.
Teams often confuse data quantity with data value. Ten thousand similar recordings provide limited benefit. Diverse samples covering varied conditions matter more. Quality and variety trump pure volume.
Incremental data collection proves more practical than waiting. Start retraining with available data. Measure improvement carefully. Collect additional samples strategically. This iterative approach builds models progressively.
Synthetic data generation supplements real recordings. Text-to-speech systems create additional samples. Data augmentation multiplies existing recordings. These techniques stretch limited real data further.
Active learning optimizes data collection efficiency. Models identify uncertain predictions. Teams prioritize collecting those specific examples. This targeted approach maximizes learning per sample.
Budget constraints limit data collection realistically. Organizations must balance cost and performance. Understanding minimum viable data prevents wasteful collection. Strategic sampling optimizes limited resources when retraining speech recognition models.
Poor Audio Quality in Training Data
Audio quality directly determines model performance. Noisy recordings confuse training algorithms. Poor quality data teaches models to expect and produce errors.
Common quality problems plague training datasets. Background noise masks speech signals. Low bitrate encoding loses critical information. Clipping distorts loud sounds. Echo and reverberation muddy audio. Each problem degrades model learning.
Recording conditions vary dramatically in real deployments. Clean studio recordings don’t match field conditions. Models trained on pristine audio fail on noisy inputs. The training-deployment mismatch causes systematic failures.
Quality standards need explicit definition and enforcement. Signal-to-noise ratio thresholds filter bad recordings. Clipping detection removes distorted samples. Echo metrics identify problematic acoustics. Automated quality checks scale to large datasets.
Some noise proves beneficial for robustness. Models need exposure to realistic conditions. Completely clean data creates brittle models. Strategic noise inclusion improves real-world performance.
Audio preprocessing improves training data quality. Noise reduction algorithms clean recordings. Normalization standardizes volume levels. Filtering removes unwanted frequencies. These techniques salvage marginal recordings.
Quality control workflows catch problems early. Manual review samples datasets randomly. Automated metrics flag suspicious recordings. Annotator feedback reveals quality issues. Systematic quality management prevents garbage-in-garbage-out.
Storage and transmission affect quality significantly. Lossless formats preserve original recordings. Compression introduces artifacts. Network transmission can corrupt files. Proper data handling maintains quality throughout pipelines when retraining speech recognition models.
Imbalanced Dataset Composition
Training data must represent actual usage patterns accurately. Skewed distributions create biased models. Imbalanced datasets cause predictable performance problems.
Demographic imbalances affect recognition accuracy. Models trained predominantly on male voices struggle with female speakers. Age imbalances disadvantage elderly users. Accent underrepresentation hurts specific populations. These biases create unfair outcomes.
Content imbalances cause systematic errors. Overtraining on common phrases neglects rare vocabulary. Domain-specific terms need adequate representation. Edge cases require sufficient examples. Balanced content coverage ensures comprehensive capability.
Recording condition imbalances reduce robustness. Clean audio dominates while noisy samples lack. Quiet environments overrepresent compared to realistic settings. This imbalance creates deployment failures.
Temporal imbalances introduce hidden biases. Recent data may not represent long-term patterns. Seasonal variations need coverage across time. Trends change linguistic usage patterns. Historical balance matters for stability.
Quantifying imbalances requires systematic analysis. Demographic breakdowns reveal representation gaps. Content frequency distributions show vocabulary imbalances. Acoustic condition categorization exposes quality skew. Data profiling tools automate this analysis.
Rebalancing strategies correct identified imbalances. Stratified sampling ensures proportional representation. Oversampling minorities increases their weight. Undersampling majorities reduces dominance. Synthetic generation fills representation gaps.
Perfect balance proves impossible and unnecessary. Some natural imbalances reflect reality. Prioritize balancing factors affecting target users. Focus rebalancing efforts where impact matters most when retraining speech recognition models.
Incorrect Transcription and Annotation Errors
Ground truth labels teach models what correct outputs look like. Transcription errors mislead training algorithms. The model learns incorrect patterns from bad labels.
Human transcription introduces multiple error types. Mishearing causes wrong word choices. Attention lapses create missing segments. Inconsistent conventions confuse models. Fatigue degrades transcriber accuracy over time.
Common annotation mistakes plague speech datasets. Homophones get transcribed incorrectly. Proper nouns lack capitalization consistency. Punctuation varies across annotators. These inconsistencies harm model learning.
Quality control catches annotation errors. Multiple annotators transcribe each sample independently. Agreement rates measure consistency. Disagreements trigger review. This redundancy improves label quality.
Automated validation identifies suspicious transcriptions. Length mismatches between audio and text flag problems. Out-of-vocabulary words suggest errors. Phonetic implausibility indicates mishearing. These checks catch obvious mistakes.
Annotator training improves consistency. Style guides define conventions explicitly. Regular feedback corrects systematic mistakes. Periodic testing validates annotator quality. Investment in annotators pays dividends.
Consensus mechanisms combine multiple annotations. Majority voting selects most common transcriptions. Weighted averaging considers annotator reliability. Machine learning models synthesize multiple inputs. These techniques improve overall quality.
Error propagation compounds problems downstream. Bad transcriptions teach incorrect pronunciations. Pronunciation errors affect downstream tasks. Systematic errors become embedded in models. Catching errors early prevents cascading failures when retraining speech recognition models.
Inappropriate Model Architecture Choices
Model architecture fundamentally determines capabilities. Wrong architecture choices limit achievable performance. No amount of data fixes architectural mismatches.
Different architectures suit different requirements. Recurrent networks handle variable-length sequences. Convolutional networks extract local patterns. Transformer models capture long-range dependencies. Hybrid approaches combine multiple techniques.
Size considerations affect performance and efficiency. Larger models generally perform better. Computational constraints limit practical sizes. Mobile deployment demands smaller architectures. Server deployment allows massive models.
Legacy architecture limitations hamper modern performance. Older models lack attention mechanisms. They cannot leverage modern training techniques. Starting from outdated architectures wastes effort. Modern architectures provide better starting points.
Domain-specific architectures optimize for particular tasks. End-to-end models handle full pipelines. Modular designs enable component specialization. Streaming architectures support real-time processing. Batch architectures maximize throughput.
Transfer learning leverages pre-trained architectures. Starting from scratch rarely makes sense. Pre-trained models encode linguistic knowledge. Fine-tuning adapts them efficiently. Architecture choice affects transfer learning success.
Experimentation identifies optimal architectures. Multiple candidates get trained in parallel. Systematic evaluation compares performance. Architecture search automates exploration. This investment pays off long-term.
Computational budget constrains architecture options. Training costs scale with model size. Inference latency affects user experience. Memory requirements limit deployment options. Practical constraints guide architecture decisions when retraining speech recognition models.
Suboptimal Hyperparameter Selection
Hyperparameters control the training process itself. Poor choices slow learning or prevent convergence. Optimal settings differ across datasets and architectures.
Learning rate proves most critical. Too high causes training instability. Too low wastes time and may never converge. The right rate enables efficient learning. Finding optimal rates requires experimentation.
Batch size affects training dynamics. Larger batches provide stable gradients. Smaller batches enable more frequent updates. Memory constraints limit maximum size. The tradeoff balances speed and stability.
Optimizer selection influences convergence. Adam adapts learning rates automatically. SGD with momentum provides good baselines. Specialized optimizers suit specific problems. Each optimizer has optimal hyperparameters.
Regularization prevents overfitting. Dropout randomly disables neurons during training. Weight decay penalizes large parameters. Data augmentation expands effective dataset size. Proper regularization improves generalization.
Training duration determines final performance. Too short stops before convergence. Too long wastes resources without improvement. Early stopping monitors validation metrics. This prevents both undertraining and overtraining.
Hyperparameter search automates optimization. Grid search tries combinations systematically. Random search samples parameter spaces. Bayesian optimization models search spaces. Automated search finds better settings than manual tuning.
Different training phases need different settings. Initial training uses aggressive learning rates. Fine-tuning requires gentler adjustments. Learning rate schedules adapt over training. Stage-appropriate settings optimize overall process.
Computing costs constrain hyperparameter tuning. Each configuration requires full training. Limited budget forces strategic choices. Transfer learning from similar tasks guides initial settings when retraining speech recognition models.
Inadequate Validation and Testing Procedures
Training metrics alone provide insufficient evaluation. Models must perform well on unseen data. Proper validation catches overfitting and dataset-specific quirks.
Validation set composition critically affects evaluation. Hold-out sets must represent target deployment. Random splits may miss important edge cases. Stratified splitting ensures representative samples. Temporal splits test real-world deployment scenarios.
Test set contamination invalidates evaluations. Training data leaking into test sets inflates metrics. Duplicate detection prevents contamination. Strict separation maintains evaluation integrity. Clean test sets provide honest assessments.
Multiple evaluation metrics capture different aspects. Word error rate measures overall accuracy. Character error rate provides finer granularity. Semantic accuracy evaluates meaning preservation. No single metric tells the complete story.
Demographic breakdown reveals bias problems. Performance varies across speaker groups. Gender, age, and accent analysis identifies gaps. Fair evaluation considers all user populations. Aggregate metrics hide important disparities.
Domain-specific evaluation assesses practical value. Industry terminology recognition matters for specialized applications. Rare event handling affects critical use cases. Custom metrics align with business objectives. Generic benchmarks miss domain requirements.
Statistical significance testing validates improvements. Small metric changes may reflect random variation. Confidence intervals quantify uncertainty. Hypothesis testing confirms real improvements. Rigorous statistics prevent false conclusions.
Continuous evaluation tracks production performance. Model behavior drifts over time. Real-world metrics differ from lab evaluations. Production monitoring catches degradation early. Deployment validation closes the evaluation loop when retraining speech recognition models.
Ignoring Domain-Specific Requirements
Generic models perform poorly on specialized tasks. Medical terminology differs vastly from casual conversation. Legal language follows unique patterns. Each domain has specific requirements.
Vocabulary differences demand adaptation. Technical jargon needs explicit training. Brand names require special handling. Industry acronyms confuse generic models. Domain lexicons guide retraining.
Speaking patterns vary across contexts. Formal presentations differ from informal chats. Customer service follows predictable scripts. Emergency calls have unique characteristics. Context-aware training improves performance.
Acoustic conditions differ by application. Call centers have specific background noise. Manufacturing floors create industrial sounds. Vehicles introduce road and engine noise. Training must match deployment conditions.
Performance priorities vary by use case. Medical transcription demands extreme accuracy. Real-time captioning prioritizes speed. Voice commands require immediate response. Different applications need different optimizations.
Regulatory requirements affect deployment. Healthcare data faces HIPAA restrictions. Financial services require audit trails. Privacy regulations limit data usage. Compliance constraints guide retraining decisions.
User expectations differ across domains. Professional users tolerate complexity for accuracy. Consumer applications prioritize ease of use. Enterprise deployments need integration capabilities. Understanding users guides retraining priorities.
Failure modes have different consequences. Medication name errors can harm patients. Financial figure mistakes cause monetary loss. Address errors merely frustrate users. Critical applications demand extra care when retraining speech recognition models.
Neglecting Data Augmentation Techniques
Limited real data constrains model performance. Data augmentation artificially expands training sets. These techniques multiply available samples effectively.
Speed perturbation varies playback rates. Faster speech simulates hurried speakers. Slower speech matches deliberate speaking. Rate variation improves temporal invariance. This simple technique provides significant benefits.
Pitch shifting modifies voice characteristics. Higher pitches simulate different speakers. Lower pitches expand demographic coverage. Pitch variation improves speaker independence. The model learns voice-invariant features.
Background noise injection improves robustness. Adding realistic noise simulates deployment conditions. Varying noise types covers diverse environments. Signal-to-noise ratio variation teaches noise handling. Models become robust to real-world conditions.
Reverberation augmentation simulates acoustic spaces. Room impulse responses model reflections. Varying spaces improve generalization. The model adapts to different acoustic environments. This prepares for diverse deployment locations.
Time stretching modifies duration without affecting pitch. Temporal variations improve rhythm handling. This complements speed perturbation. Combined temporal augmentations increase robustness.
Mixup techniques blend multiple samples. Audio mixing creates intermediate examples. This regularization improves generalization. The technique works particularly well for speech.
SpecAugment masks frequency and time regions. Random masking forces robust feature learning. The model cannot rely on specific patterns. This prevents overfitting to training data.
Combining multiple augmentation techniques multiplies diversity. Careful selection balances variation and realism. Too much augmentation creates unrealistic samples. Strategic augmentation expands data effectively when retraining speech recognition models.
Improper Transfer Learning Application
Starting from pre-trained models accelerates development. Transfer learning leverages existing knowledge. Improper application wastes this opportunity.
Source model selection critically affects results. Matching source and target domains helps. Language similarity between models matters. Architecture compatibility enables transfer. Poor source selection limits transfer benefits.
Freezing strategies determine adaptation depth. Freezing early layers preserves low-level features. Fine-tuning later layers adapts to specifics. Full fine-tuning updates everything. The right strategy depends on data availability.
Learning rate scheduling differs for transfer. Lower rates preserve pre-trained knowledge. Higher rates enable rapid adaptation. Two-stage approaches combine both. Discriminative learning rates vary by layer.
Catastrophic forgetting destroys pre-trained knowledge. Aggressive fine-tuning overwrites useful features. Regularization preserves important weights. Knowledge distillation maintains capabilities. Careful tuning prevents forgetting.
Domain adaptation techniques smooth transfer. Adapting acoustic models to new conditions. Adjusting language models for vocabulary. Feature-level adaptation aligns distributions. These techniques improve transfer success.
Multi-task learning enhances transfer. Related tasks share beneficial knowledge. Joint training on multiple objectives. Task-specific heads specialize appropriately. This approach maximizes knowledge transfer.
Evaluation validates transfer effectiveness. Comparing transferred models to random initialization. Measuring improvement over baseline. Transfer learning should provide significant gains. Marginal improvements suggest poor application when retraining speech recognition models.
Overlooking Acoustic Model Updates
Speech recognition comprises multiple components. Acoustic models convert audio to phonemes. Language models predict word sequences. Many teams focus exclusively on one component.
Acoustic model retraining adapts to new speakers. Individual voice characteristics vary widely. Regional accents require specific training. Age-related speech patterns need coverage. Comprehensive acoustic training improves recognition.
Pronunciation variations demand attention. Words can sound different across dialects. Casual speech drops or modifies sounds. Fast speech causes phonetic changes. Acoustic models must handle variation.
Recording equipment affects acoustic patterns. Different microphones have unique characteristics. Audio codecs introduce artifacts. Telephony systems band-limit frequencies. Acoustic training must match equipment.
Environmental acoustics create challenges. Room reverberation colors speech signals. Background talkers create interference. HVAC systems add constant noise. Training on varied acoustics improves robustness.
Feature extraction affects acoustic modeling. Mel-frequency cepstral coefficients provide standard features. Alternative representations offer different strengths. Feature choices interact with model architecture. Coordinated optimization improves performance.
End-to-end models blur acoustic-language boundaries. Single models handle entire pipelines. These approaches require different training strategies. Understanding architecture affects retraining decisions.
Balancing acoustic and language model updates. Both components contribute to accuracy. Coordinated retraining optimizes overall performance. Neglecting either component limits improvements when retraining speech recognition models.
Insufficient Computational Resources
Model training demands substantial computation. Inadequate resources prolong development cycles. Resource constraints force suboptimal compromises.
GPU availability limits training throughput. Modern training requires powerful GPUs. Multiple GPUs enable data parallelism. Insufficient GPUs bottleneck development. Cloud resources provide flexible scaling.
Memory constraints restrict model sizes. Large models need substantial RAM. Batch sizes scale with memory. Out-of-memory errors crash training. Right-sizing resources enables experimentation.
Storage requirements grow rapidly. Audio files consume significant space. Multiple training runs accumulate artifacts. Fast storage improves data loading. Adequate storage prevents bottlenecks.
Network bandwidth affects distributed training. Multi-node training communicates frequently. Slow networks limit scaling efficiency. High-bandwidth connections enable large-scale training. Infrastructure capabilities determine scale.
Training time affects iteration speed. Faster training enables more experiments. Quick feedback loops accelerate development. Excessive training time slows progress. Computational power determines velocity.
Cost considerations constrain resources. Cloud computing charges by usage. On-premise hardware requires capital investment. Budget limitations force tradeoffs. Strategic resource allocation maximizes impact.
Optimization techniques reduce resource needs. Mixed precision training uses less memory. Gradient accumulation simulates larger batches. Model pruning reduces sizes. These techniques stretch limited resources when retraining speech recognition models.
Poor Learning Rate Scheduling
Learning rates control training dynamics. Fixed rates rarely work optimally. Dynamic schedules improve convergence and final performance.
Initial learning rates determine training start. Too high causes immediate divergence. Too low wastes early training time. Finding the right starting point proves critical. Learning rate finders automate discovery.
Decay schedules reduce rates over training. Step decay drops at intervals. Exponential decay gradually reduces. Cosine annealing smoothly transitions. Each schedule has different characteristics.
Warmup periods stabilize early training. Starting with low rates prevents instability. Gradually increasing prevents early divergence. This technique proves especially important for large models.
Cyclical learning rates vary periodically. Rates oscillate between bounds. This escapes local minima. The technique can improve final performance. Careful tuning maximizes benefits.
Adaptive learning rates respond to progress. Plateau detection triggers reductions. Validation metrics guide adjustments. Automatic adaptation simplifies tuning. These methods reduce manual intervention.
Layer-specific rates optimize fine-tuning. Early layers need smaller adjustments. Later layers adapt more freely. Discriminative rates preserve pre-trained knowledge. This proves crucial for transfer learning.
Monitoring loss curves guides schedule adjustments. Plateaus suggest reducing rates. Oscillations indicate excessive rates. Divergence requires immediate correction. Responsive scheduling improves outcomes when retraining speech recognition models.
Failing to Monitor Training Progress
Training runs for hours or days. Problems emerge gradually during training. Without monitoring, teams discover failures too late.
Loss curves reveal training dynamics. Smooth decrease indicates healthy learning. Oscillations suggest instability. Plateaus show learning slowdown. Divergence signals serious problems.
Validation metrics track generalization. Training accuracy alone misleads. Overfitting appears in training-validation gaps. Early stopping prevents wasted training. Regular validation checkpoints catch problems.
Learning rate impact shows in metrics. Too high creates instability. Too low shows minimal progress. Monitoring reveals rate problems. Adjustments improve training efficiency.
Gradient norms indicate optimization health. Exploding gradients signal instability. Vanishing gradients prevent learning. Monitoring enables corrective action. Gradient clipping solves many problems.
Sample predictions provide qualitative insights. Reviewing specific examples reveals failure modes. Metrics don’t capture all problems. Qualitative analysis complements quantitative. Regular sampling catches systematic errors.
Resource utilization affects efficiency. GPU usage should stay near maximum. Low utilization indicates bottlenecks. Memory usage shows sizing issues. Monitoring optimizes infrastructure.
Checkpoint management enables recovery. Regular saving prevents starting over. Version tracking enables comparisons. Automatic cleanup prevents storage overflow. Good practices minimize lost work when retraining speech recognition models.
Inadequate Production Deployment Planning
Training succeeds but deployment fails. Production environments differ from development. Careful planning bridges this gap.
Model serving infrastructure needs preparation. Real-time requirements demand low latency. Batch processing allows higher throughput. Infrastructure choices affect user experience. Planning prevents deployment surprises.
Versioning strategies enable safe rollouts. A/B testing compares models safely. Canary deployments limit blast radius. Blue-green deployment enables instant rollback. These patterns reduce deployment risk.
Performance monitoring tracks production behavior. Latency metrics ensure responsiveness. Accuracy tracking catches degradation. Error analysis identifies problems. Continuous monitoring maintains quality.
Fallback mechanisms handle model failures. Older models provide backup. Rule-based systems catch edge cases. Graceful degradation maintains functionality. Reliability engineering prevents outages.
Load testing validates scalability. Traffic spikes shouldn’t cause failures. Autoscaling maintains performance. Capacity planning prevents bottlenecks. Testing reveals limits before users do.
Cost optimization controls expenses. Inference costs scale with usage. Efficient serving reduces bills. Batching improves throughput. Cloud cost management prevents surprises.
Compliance requirements affect deployment. Data privacy regulations restrict processing. Audit requirements demand logging. Security standards require encryption. Meeting requirements avoids legal problems when retraining speech recognition models.
Neglecting Continuous Model Maintenance
Deployment isn’t the endpoint. Models degrade over time naturally. Continuous maintenance maintains performance.
Performance monitoring detects degradation. Metrics decline gradually or suddenly. Trend analysis predicts future problems. Early detection enables proactive response. Monitoring systems automate tracking.
Data drift causes accuracy decline. Real-world inputs change over time. Models don’t adapt automatically. Drift detection identifies problems. Retraining addresses drift systematically.
User feedback reveals practical problems. Complaint patterns highlight issues. Support tickets indicate systematic errors. User surveys gather structured feedback. This qualitative data guides improvements.
Regular retraining maintains quality. Scheduled updates incorporate new data. Ad-hoc retraining responds to problems. Continuous learning adapts automatically. Maintenance strategies vary by needs.
Model versioning tracks evolution. Each retraining creates new versions. Comparison enables regression detection. Version control supports rollback. Systematic tracking maintains history.
Documentation captures knowledge. Training procedures need documentation. Dataset descriptions aid understanding. Decision rationales preserve context. Good documentation supports long-term maintenance.
Team knowledge prevents bus factor problems. Multiple team members understand systems. Training ensures knowledge transfer. Documentation supplements memory. Organizational resilience requires planning when retraining speech recognition models.
Frequently Asked Questions
How much training data do I need for effective retraining?
Data requirements vary significantly based on multiple factors. Starting model quality affects additional needs substantially. Fine-tuning pre-trained models needs less data than training from scratch. Domain similarity between existing knowledge and target application reduces requirements. Generally, hundreds of hours provide good baselines for modern models. Complex domains or significant distribution shifts demand thousands of hours. Active learning and strategic sampling maximize efficiency. Start with available data and expand based on measured gaps.
What audio quality standards should training data meet?
Training data should match target deployment conditions closely. Signal-to-noise ratio above 20dB generally works well. Sample rates of 16kHz suffice for speech recognition. Lossless or high-bitrate formats preserve quality during processing. Avoid excessive compression artifacts that distort speech. Some realistic background noise actually improves robustness. Completely clean data creates brittle models. Validate quality through automated metrics and manual sampling. Remove severely corrupted recordings that harm learning.
How do I know when my model needs retraining?
Several indicators signal retraining needs clearly. Declining accuracy metrics over time suggest degradation. New vocabulary appearing in production indicates gaps. User complaints about specific error types reveal problems. Distribution shift metrics quantify changing inputs. Performance disparities across demographics show bias. Business expansion into new domains creates requirements. Schedule regular retraining proactively. Monitor continuously and respond to signals.
Should I retrain from scratch or fine-tune existing models?
Fine-tuning almost always works better than starting fresh. Pre-trained models encode massive linguistic knowledge. Starting from scratch wastes this valuable information. Fine-tuning adapts existing knowledge efficiently. Full retraining makes sense only when domains differ drastically. Even then, transfer learning helps. Catastrophic forgetting during fine-tuning requires careful learning rates. Most situations benefit from fine-tuning approaches.
What hyperparameters matter most for speech recognition retraining?
Learning rate proves most critical for convergence. Batch size affects training stability and speed. Number of training epochs determines final performance. Dropout rates control overfitting. Weight decay provides regularization. Optimizer choice influences convergence speed. Learning rate schedules adapt over training. Data augmentation parameters expand effective datasets. Grid search or Bayesian optimization finds good settings. Transfer similar task settings as starting points.
How can I tell if my training data has quality problems?
Multiple checks reveal quality issues systematically. Listen to random samples for obvious problems. Check transcription accuracy through spot validation. Measure audio metrics like SNR and clipping. Analyze demographic and content distributions. Compare performance across dataset segments. Poor quality shows up in training instabilities. Validation performance ceiling indicates data limits. Systematic quality control catches problems early.
What should I do if retraining makes performance worse?
Several troubleshooting steps address regression problems. Check for test set contamination first. Verify new training data quality thoroughly. Review hyperparameter choices for appropriateness. Examine learning curves for overfitting signs. Compare performance across demographic groups. Consider whether catastrophic forgetting occurred. Roll back to previous model if needed. Systematic diagnosis reveals root causes. Fix underlying problems before retraining again.
How often should speech recognition models be retrained?
Retraining frequency depends on application dynamics. Rapidly changing domains need monthly updates. Stable applications tolerate quarterly schedules. Continuous learning enables constant adaptation. Monitor degradation metrics to guide timing. Significant distribution shifts demand immediate retraining. Balance update frequency with validation thoroughness. Automated pipelines enable frequent updates safely. Establish monitoring thresholds that trigger retraining.
Can I retrain models with limited computational resources?
Resource constraints require strategic approaches. Focus on fine-tuning rather than full retraining. Use smaller model architectures. Reduce batch sizes to fit available memory. Employ gradient accumulation for effective larger batches. Leverage cloud computing for flexibility. Use mixed precision training for efficiency. Prioritize high-impact training data. Smart resource allocation achieves good results despite limitations.
What metrics should I track during speech recognition retraining?
Multiple metrics provide comprehensive evaluation. Word error rate measures overall accuracy. Character error rate offers finer granularity. Semantic accuracy evaluates meaning preservation. Real-time factor assesses speed. Confidence calibration measures uncertainty. Demographic breakdowns reveal fairness. Domain-specific metrics align with objectives. Track multiple perspectives for complete understanding. Balance competing metrics appropriately.
Read More:-How AI Enables Real-Time Voice Personalization
Conclusion

Retraining speech recognition models demands careful attention to numerous factors. Data quality fundamentally determines achievable performance. Insufficient volume, poor transcriptions, and imbalanced distributions sabotage learning. Your training data deserves rigorous quality control.
Architecture and hyperparameter choices dramatically affect outcomes. Wrong selections waste computational resources without improvement. Systematic experimentation identifies optimal configurations. Transfer learning leverages existing knowledge efficiently.
Validation procedures must catch problems before production. Comprehensive testing reveals weaknesses early. Domain-specific evaluation ensures practical value. Statistical rigor validates claimed improvements.
Domain requirements shape successful retraining. Generic approaches fail on specialized tasks. Understanding acoustic conditions, vocabulary, and user expectations guides decisions. Context-aware retraining delivers better results.
Data augmentation multiplies limited training samples. Speed variation, noise injection, and other techniques improve robustness. Strategic augmentation expands effective datasets substantially. These methods prove especially valuable with constrained data.
Transfer learning accelerates development dramatically. Starting from pre-trained models provides massive advantages. Proper freezing strategies and learning rates preserve knowledge. Careful application maximizes transfer benefits.
Production deployment requires thorough planning. Serving infrastructure must meet performance requirements. Monitoring catches degradation proactively. Fallback mechanisms maintain reliability despite problems.
Continuous maintenance keeps models current. Performance monitoring detects drift early. Regular retraining addresses degradation systematically. User feedback guides practical improvements.
Computational resources enable experimentation. Adequate GPUs, memory, and storage accelerate development. Strategic optimization stretches limited resources. Cloud computing provides flexible scaling.
Learning from common mistakes shortens your learning curve. Other teams already made these errors. Their painful lessons inform your decisions. This guide helps you avoid repeating history.
Start your next retraining effort with these insights. Plan carefully before collecting data. Validate assumptions throughout the process. Monitor progress continuously. Test thoroughly before deployment.
Your users deserve accurate speech recognition. Business objectives depend on model performance. The investment in proper retraining pays substantial dividends. Take the time to retrain speech recognition models correctly. The results will justify your careful attention to detail and best practices.